
Cloud : Way2Cloud pattern : du flat file vers un service backend Redis
🎯 Objectif : ce document à pour mission est de montrer par l'exemple une transition Legacy/IaaS vers le PaaS, d'un application qui utilise des Spool de fichiers.
le usecase ne se veut pas exhaustif et ne détaillera que l'usage des Spool depuis une application web minimaliste.
L'application, pour l'exemple ne contiendra qu'un verbe GET sur les spools, typiquement des spools de traitement de fichier :
- input
- archive
- error
👆 Remarque : le usecase décrira une transition de flat file vers Redis et pas du transport (SFTP, RabbitMQ, Kafka, etc..)
Le usecase va par contre décrire de façon complète les CRUD et la mécanique de transition.
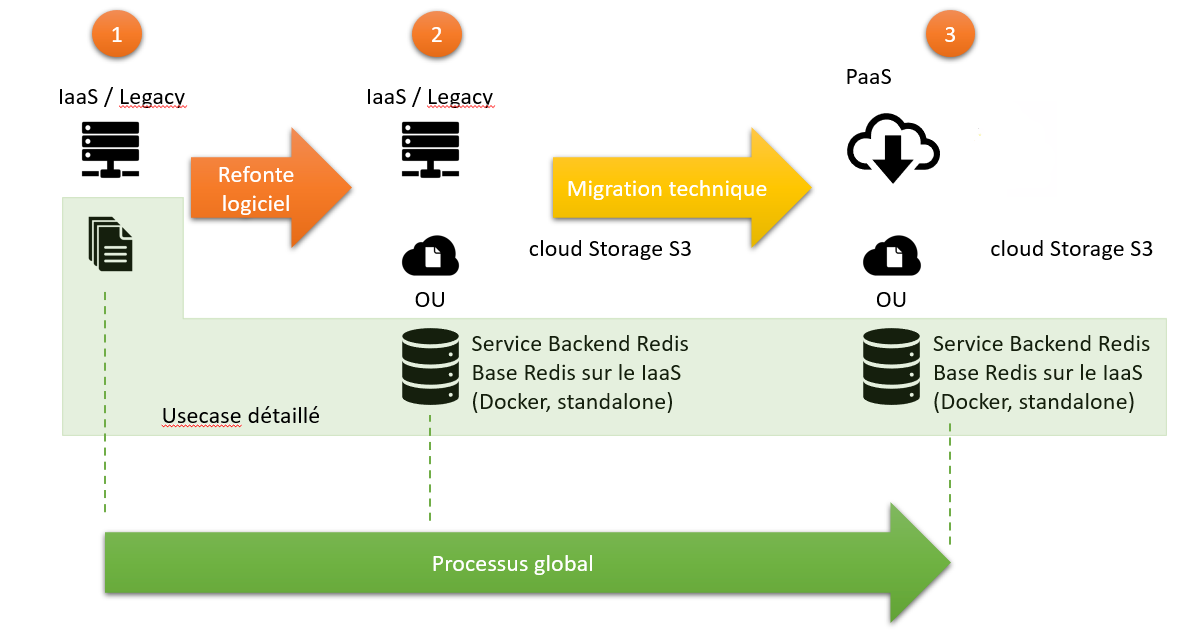
Le usecase va se concentrer sur la flèche ORANGE, cad le processus de refonte logiciel.
👆 Remarque : Pour l'exemple je vais utiliser un langage interprété dynamique full objet ou les design patterns seront facilement compréhensible : Ruby avec le framework Sinatra
Les sources de toutes les étapes seront disponibles sur Github pour tester directement
⚠️ Attention : Le usecase requière un service Redis opérationnel, c'est pourquoi je vous conseille l'usage de Docker afin d'avoir un Redis sous la main simplement.
État initiale
L'application minimaliste se construit de la manière suivante :
- Un backend File CRUD + List + flush + exist?
module Backends class File
attr_accessor :spool
def initialize(options={})
@root_path = (options[:root_path])? options[:root_path] : '/tmp/legacy-switch'
@spool = options[:spool]
@default_ext = ".txt"
end
def list
return ::Dir["#{@root_path}/#{@spool}/*#{@default_ext}"].map! {|filename| filename = ::File.basename(filename,@default_ext) }
end
def get(options = {})
return ::File.read("#{@root_path}/#{@spool}/#{options[:entry]}#{@default_ext}")
end
def delete(options)
::File.delete("#{@root_path}/#{@spool}/#{options[:entry]}#{@default_ext}")
end
def upsert(options ={})
::File.open("#{@root_path}/#{@spool}/#{options[:entry]}#{@default_ext}", 'w') { |file| file.write(options[:data]) }
end
def exist?(options)
return ::File.exist?("#{@root_path}/#{@spool}/#{options[:entry]}#{@default_ext}")
end
def flush
Dir.glob("#{@root_path}/#{@spool}/*#{@default_ext}").each { |file| ::File.delete(file)}
end
alias :update :upsert
alias :create :upsert
end
end chargé par une application Sinatra (app.rb) qui n'offre qu'une route GET /get/:name
⚠️ Attention : si vous lancez l'exemple, il n'y a pas de route / , donc il faut accéder directement à l'URL : http://localhost:<PORT>/get/<SPOOLNAME>, ex: http://localhost:9292/get/input
ℹ️ Remarque : pour initialiser et lancer une application Sinatra, il faut être dans le répertoire ou se trouve le config.ru et taper :
$ rackup ℹ️ Remarque : Il est necessaire d'installer Ruby, Rubygem et Bundler pour cela
Le loader va ressembler à :
require_relative 'lib/init'
require_relative 'lib/backends/init'
class Application < Sinatra::Base
def initialize(*args)
super(args)
puts 'Starting application'
@spooler = ::Backends::File::new spool: 'input'
puts "Applications Init. "
end
get "/get/:name" do |name|
@spooler.spool = name
@name = name
@data = []
@spooler.list.each do |item|
@data.push({:name => item,
:content => @spooler.get({:entry => item})})
end
erb :spool
end
end
on voit donc qu'il initialise le spool, et défini le route.
👆 Remarque : l'application pour bien faire devrait charger le spooler par Injection de dépendance, mais ici ce n'est pas le cas pour simplifier le code pour détailler la migration
Avec Sinatra pour que tout puisse marcher il faut deux fichiers vitaux :
config.ruqui a la charge d'initialiser l'application et de rapatrier les dépendances via BundlerGemfile: qui liste les dépendances
tel que, config.ru :
require 'rubygems'
require 'bundler'
Bundler.require
require './app.rb'
run Application et Gemfile :
source 'https://rubygems.org'
gem 'sinatra', '~> 2.0'
gem 'thin' Il faut aussi :
- des vues et des ressources public (styles CSS)
ℹ️ Remarque : le code de partie CSS ne sera pas décrit ici, c'est juste pour faire une table HTML pas trop moche 😁
- Un layout HTML basique :
<html><head>
<title> Application</title>
<link rel="stylesheet" type="text/css" href="/style.css" />
</head>
<body>
<%= yield %>
</body>
</html> - et la vue en ERB de la route GET /get/:name :
<h1>display content of spool : "<%= @name %>"</h1>
<table class="styled-table">
<thead>
<tr>
<th> Entry </th>
<th> Value </th>
</tr>
<thead>
<tbody>
<% @data.each do |element| %>
<tr><td><%=element[:name]%></td><td><%=element[:content]%></td></tr>
<% end %>
</tbody>
<tfoot>
<tr>
<th scope="row"> Total entries</th>
<td> <%= @data.size %></td>
</tr>
</tfoot>
</table> Pré-requis de test
je vous conseille pour parcourir ce document de tester en même temps :
Et pour tester il faut injecter des données de test dans les spools avec le script inject.rb (dans l'étape1 de l'archive) :
# ruby inject.rb
Start injections :
* Check root path done
* Check spool paths done
* Populate files in spools done le script va créer la structure suivante :
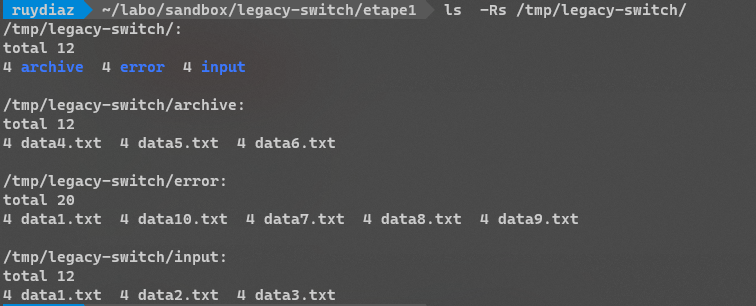
👆 Remarque : le script est idempotent
Premier lancement de l'application

Si on lance le service avec rackup et qu'on accède à l'URL http://localhost:9292/get/input on obtient :
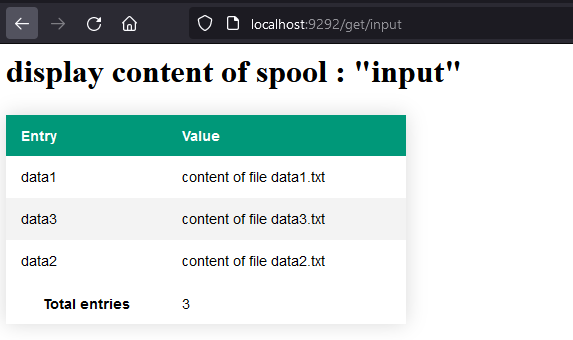
ℹ️ Remarque : on peut visualiser les autres Spool en changeant la fin de l'URL.
Principe de la migration
Le process de migration, depuis l'étape initiale (1) se fera en 5 étapes, tel que :
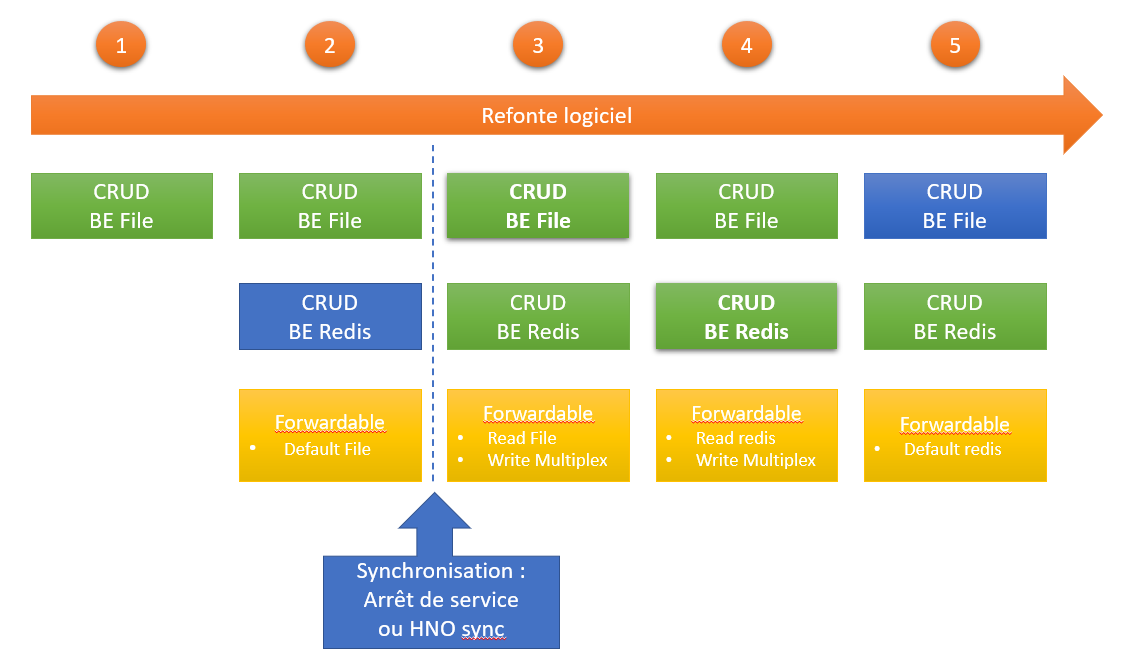
ℹ️ Remarque : on voit un jalon structurant de synchro qui va nécessiter un script externe qui sera détaillé en tant voulu.
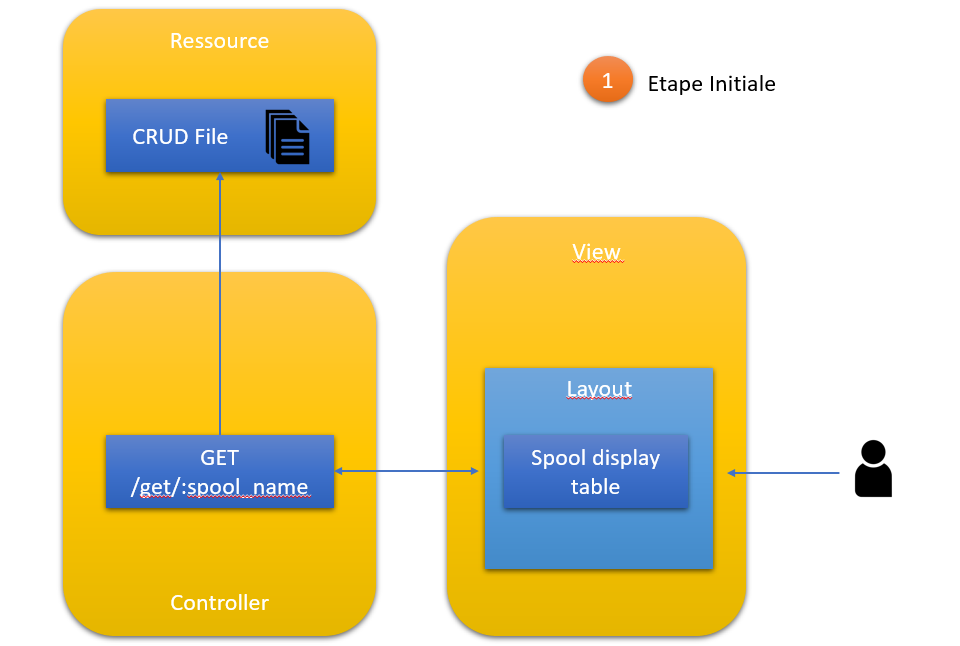
Etape initiale
Synoptique
Etape 2 : créer un BE redis un un proxy Forwardable
Synoptique
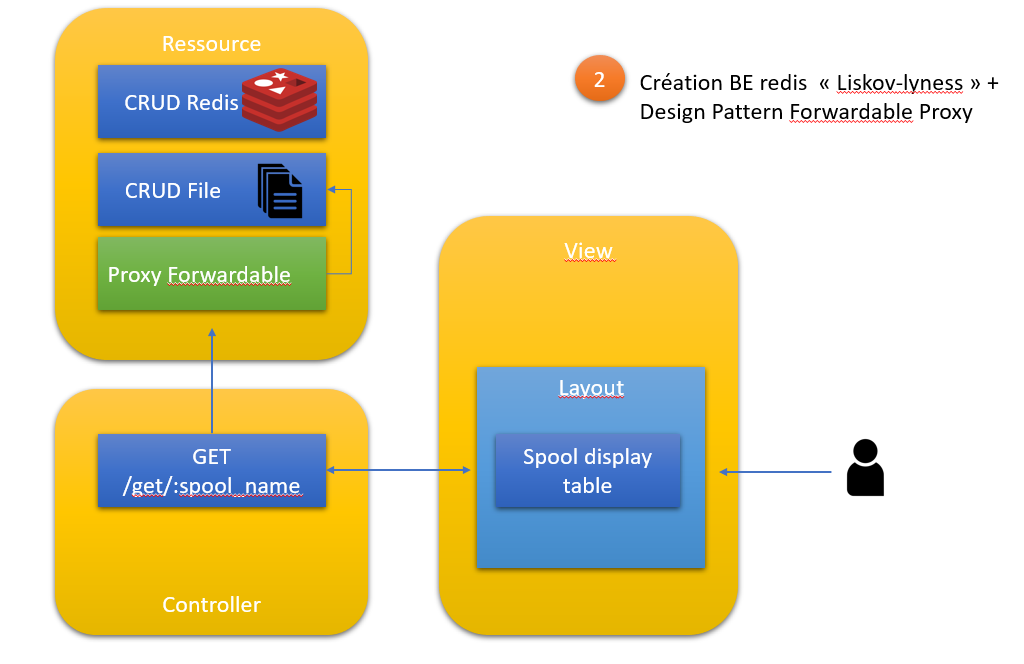
Principe
En premier on va ajouter un BE Redis, selon le principe de Liskov, cad, iso prototype :
require 'redis'
module Backends
class Redis
attr_accessor :spool
def initialize(options={})
@spool = options[:spool]
spoolmap = {'input' => 10 , 'archive' => 11 , 'error' => 12}
conf = { :host => 'localhost',
:port => '6379',
:db => spoolmap[@spool]}
@store = ::Redis.new conf
end
def list
return @store.keys('*')
end
def get(options = {})
return @store.get(options[:entry])
end
def delete(options)
@store.del options[:entry]
end
def upsert(options ={})
@store.set options[:entry], options[:data]
end
alias :update :upsert
alias :create :upsert
def exist?(options = {})
return ( not @store.get(options[:key]).nil? )
end
def flush
@store.flushdb
end
end
end👆 Remarque : le BE est fait pour, mapper les spool sur les bases 10, 11 et 12 du serveur Redis (en espérant ne pas pourrir vos propres bases, si vous en aviez déjà)
Ensuite, on va ajouter un Proxy Forwardable (voir Design pattern Forwarding et Proxy
tel que :
require 'forwardable'
class Spooler
extend Forwardable
def_delegators :@backend, :list, :get , :spool, :spool=, :delete, :upsert, :create, :update
def initialize (options = {})
spool = (options[:spool])? options[:spool] : 'input'
@backend = options[:backend]::new spool: spool
end
end On voit qu'il forwarde sur le BE File et s'init sur le spool input par défaut

Si on lance l'application à l'étape deux rien ne va changer visuellement et on n'utilise pas encore le BE Redis :
mais on voit qu'on initialise bien le backend
Jalon de synchronisation
Avant de faire la mise en prod de l'étape 3 (juste avant), il faut synchroniser les BE : pour cela un script est utile qui utilise les deux backend, ce qui va permettre de QUALIFIER en partie le backend Redis,
Celui-ci dans notre cas serait trivial (avec un vraie gestion de configuration et une injection de dépendance il serait a peine plus compliqué, voir en ruby :
le script :
require_relative 'lib/backends/init'
puts 'Start Sync : '
['input','archive','error'].each do |spool|
print "* Sync : #{spool}"
fileBE = ::Backends::File::new spool: spool
redisBE = ::Backends::Redis::new spool: spool
redisBE.flush
fileBE.list.each do |entry|
redisBE.create entry: entry, data: fileBE.get({entry: entry})
end
puts ' done'
end Si on l'exectute, on obtient :
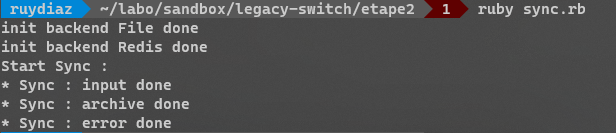
ℹ️ Remarque : le script peut être rejoué, mais il flush la base Redis. il ne s'agit pas d'une vraie idempotence.
Etape 3 : transformation du proxy pour faire du write multiplex
Synoptique
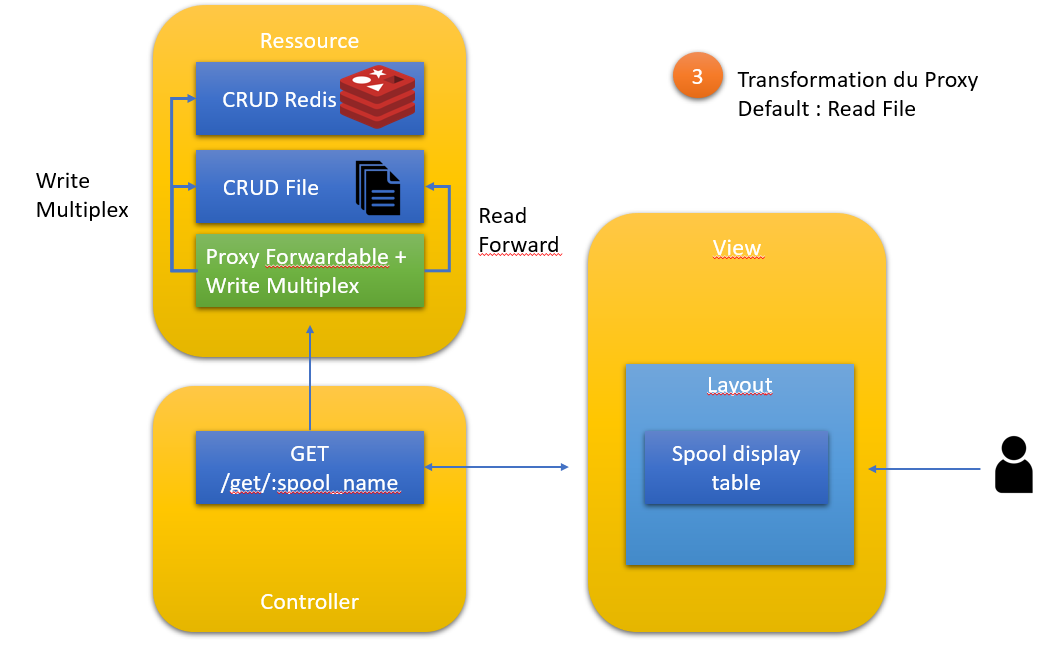
Principe
On va devoir modifier le Proxy tel que :
class Spooler
attr_reader :default
extend Forwardable
def_delegators :@default_backend, :list, :get , :spool, :spool=, :create, :update
def initialize (options = {})
@default = options[:default]
options = { spool: (options[:spool])? options[:spool] : 'input' }
@BE = {:redis => ::Backends::Redis::new options,
:file => ::Backends::File::new options}
@default_backend = @BE[@default]
end
def delete(options)
@BE.values.each {|be| be.delete(options)}
end
def upsert(options)
@BE.values.each {|be| be.upsert(options)}
end
end
On voit donc la notion de backend par défaut et delete et upsert deviennent des multiplexer sur les DEUX backend
On doit donc modifier le loader de l'application pour prendre en compte ce nouveau proxy :
require_relative 'lib/backends/init'
require_relative 'lib/init'
class Application < Sinatra::Base
def initialize(*args)
super(args)
puts 'Starting application'
@spooler = ::Spooler::new default: :file
puts "Applications Init. "
end
get "/get/:name" do |name|
@backend = @spooler.default
@spooler.spool = name
@name = name
@data = []
@spooler.list.each do |item|
@data.push({:name => item,
:content => @spooler.get({:entry => item})})
end
erb :spool
end
end
la modification reste mineur (prototype)
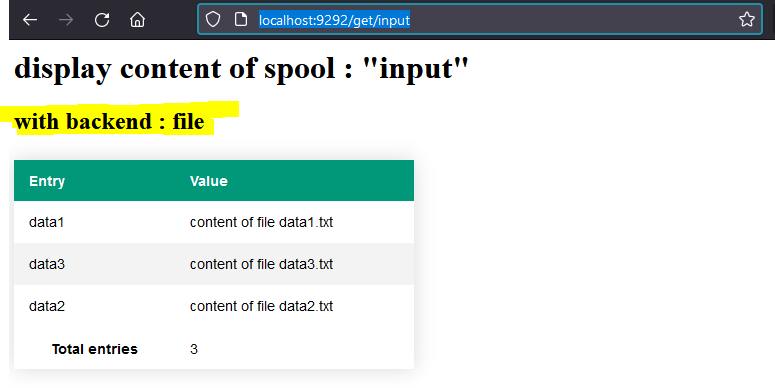
👆 Remarque : pour faciliter la compréhension j'ai patché la vue le controller sur la route GET /get/:name pour afficher le nom du backend utilisé , le code de la vue devient :
<h1>display content of spool : "<%= @name %>"</h1>
<h2> with backend : <%= @backend %> </h2>
<table class="styled-table">
<thead>
<tr>
<th> Entry </th>
<th> Value </th>
</tr>
<thead>
<tbody>
<% @data.each do |element| %>
<tr><td><%=element[:name]%></td><td><%=element[:content]%></td></tr>
<% end %>
</tbody>
<tfoot>
<tr>
<th scope="row"> Total entries</th>
<td> <%= @data.size %></td>
</tr>
</tfoot>
</table> Si on lance l'application, nous n'avons toujours pas changé de BACKEND par défaut, donc nous devons obtenir :
⚠️ ATTENTION : ici, je rappelle notre application est minimaliste, dans un cas réel le PROXY DOIT être appelé en lieu et place du backend PARTOUT ( IHM, Worker potentiel, CLI, etc .... )
ℹ️ Remarque : Les opérations en écriture ne sont pas testées ici, le code de l'appli aurait été trop long, mais nous savons que l'UPSERT marche car le script de synchronisation l'a testé
dans une vraie application, on aurait eu des routes POST, PUT DELETE, et de jolis formulaires
Dans la vraie vie, Ruby ne serait utilisé que pour les backends, script CLI, Worker, comme Sidekiq par exemple avec un flushing/dump sur du RabbitMQ.
Pour faire l'IHM on aurait du Svelte ou du ReactJS
J'insiste aussi sur le fait que je décris un processus et les design patterns à utiliser et cela dans le langage du projet.
les opération en lecture ne sont pas encore qualifiées
Etape4 : la mise en service avec double RUN
On inverse , ici la modification est ridicule, on change le BE par défaut dans le loader de l'application.
Pré-requis : on vérifié dans la base Redis que tout est OK
cela peut se faire avec la CLI redis, tel que :
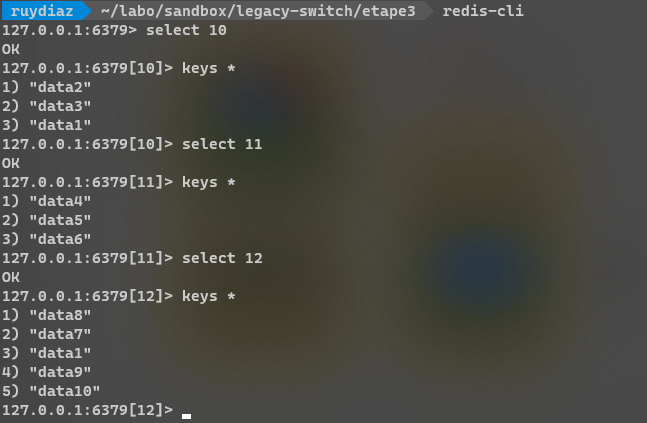
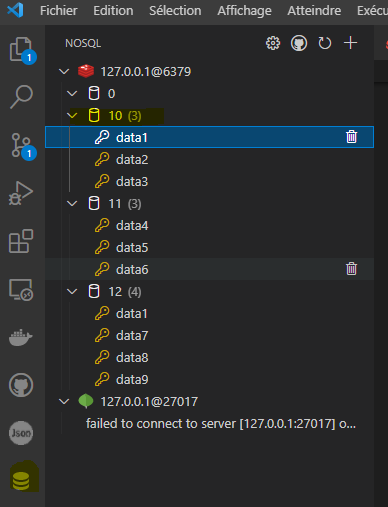
mais aussi, si vous utiliser VScode, avec l'extension Database Client :
Synoptique
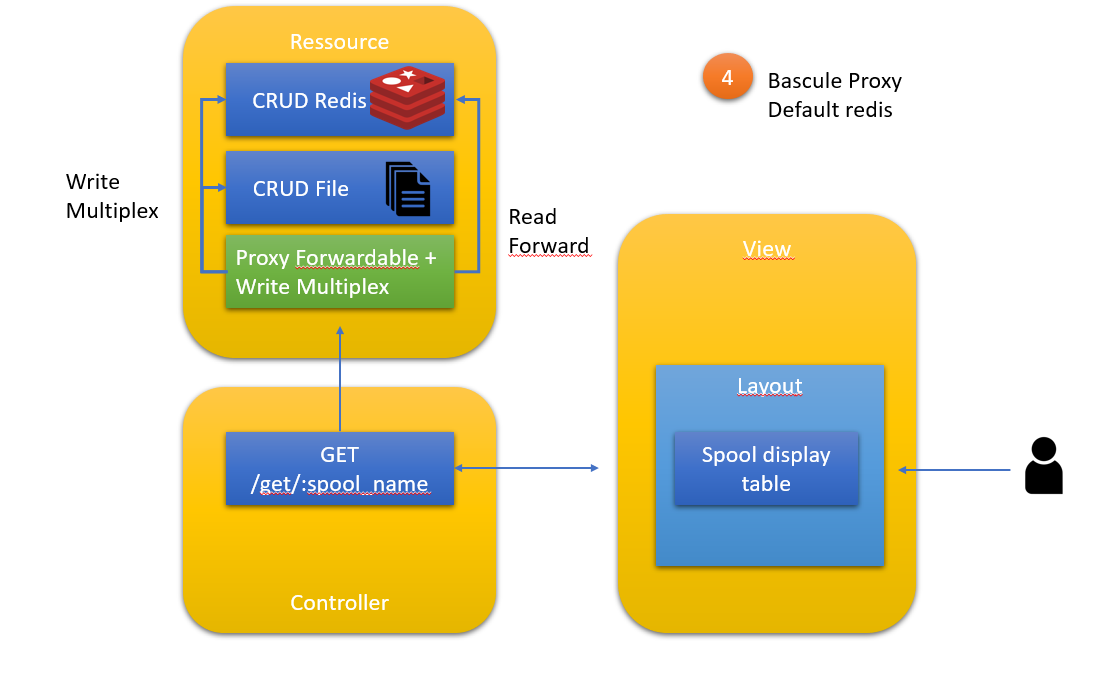
Principe
require_relative 'lib/backends/init'require_relative 'lib/init'
class Application < Sinatra::Base
def initialize(*args)
super(args)
puts 'Starting application'
@spooler = ::Spooler::new default: :redis
puts "Applications Init. "
end
get "/get/:name" do |name|
@backend = @spooler.default
@spooler.spool = name
@name = name
@data = []
@spooler.list.each do |item|
@data.push({:name => item, :content => @spooler.get({:entry => item})})
end
erb :spool
end
end
la modification unique est ligne 9
si on lance l'application on va donc obtenir :
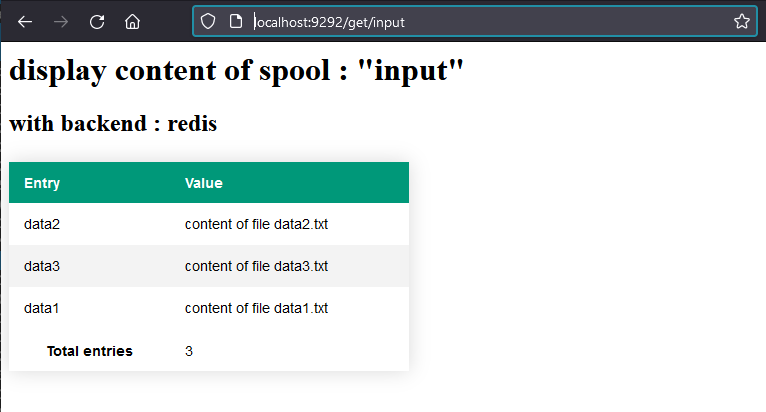
Ici les données viennent bien du BE Redis pour le prouvez, vous pouvez supprimer une entrée sur la base 10 => input, tel que
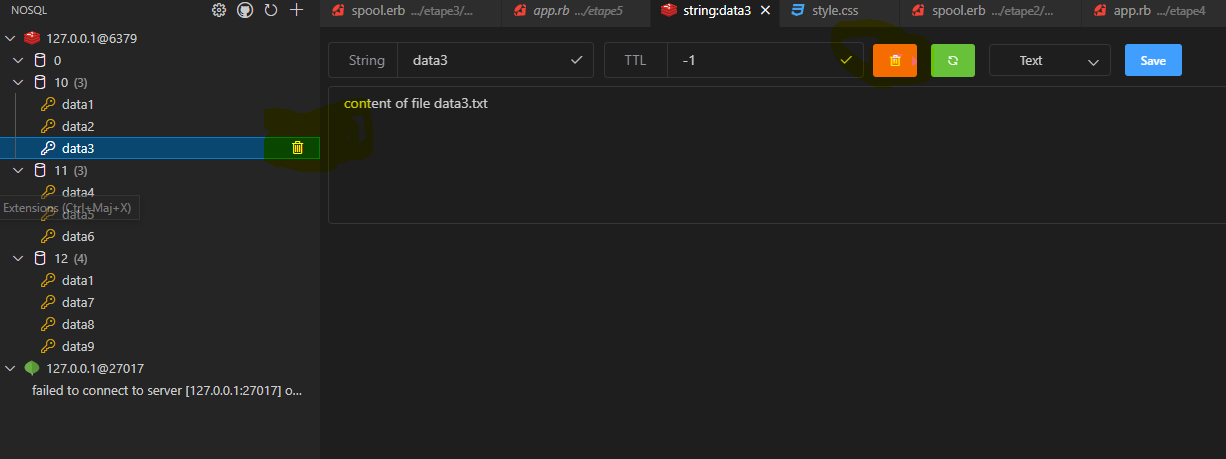
ou via la CLI avec :
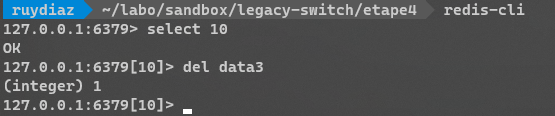
on doit donc obtenir, si l'appli tourne :
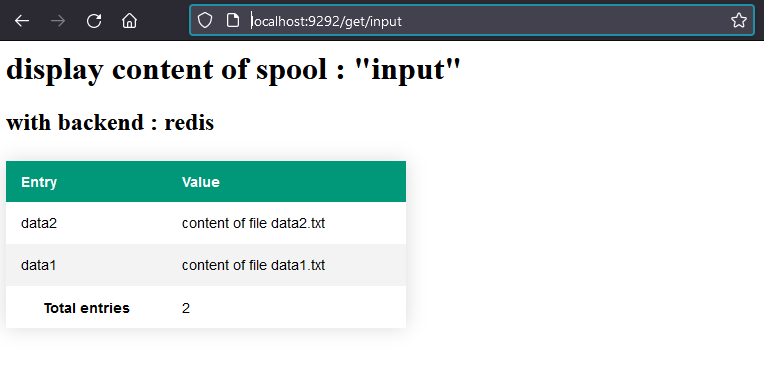
CQFD
⚠️ Attention : ce que je viens de faire en cas réel est très mal, vue que je viens de désynchroniser les deux BE !!! si vous voulez revenir en arrière dans la demo vous pouvez utiliser la synchro
MAIS attention dès l'étape5, la source autoritaire deviendra Redis, à l'étape 4 les deux bases doivent êtres synchrones, dans la vraie vie si on devait les réaligner avec de gros volumes de données
Il faudrait un script de synchro plus complexe et idempotent !!!
Etape 5 : retour en Proxy forward
Après une validation en service régulier, le Proxy n'a donc plus besoin de faire du multiplexage en écriture
Synoptique
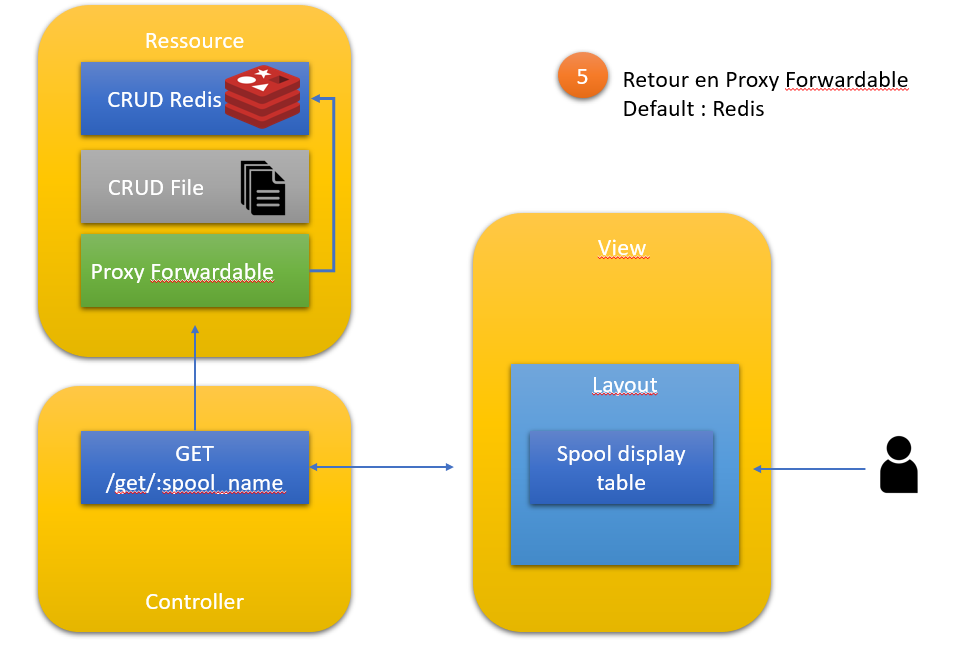
Principe
On va modifier une dernière fois le proxy pour ne plus que forwarder sur le backend par défaut :
require 'forwardable'
class Spooler
attr_reader :default
extend Forwardable
def_delegators :@default_backend, :list, :get , :spool, :spool=, :create, :update, :delete, :upsert
def initialize (options = {})
@default = options[:default]
options = { spool: (options[:spool])? options[:spool] : 'input' }
@BE = {:redis => ::Backends::Redis::new(options), :file => ::Backends::File::new(options)}
@default_backend = @BE[@default]
end
end
On va checker l'application :
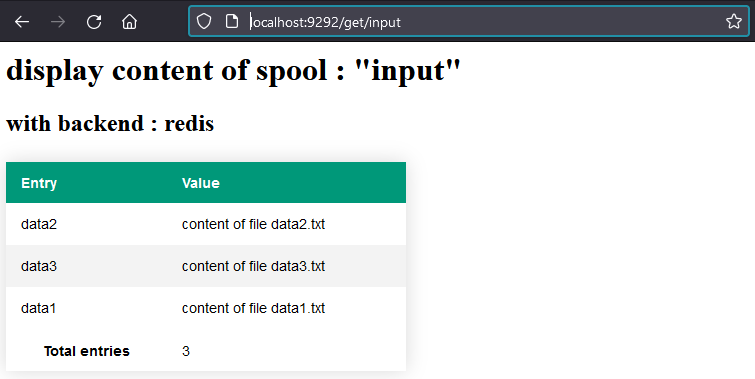
cette fois-ci on ne travail plus qu'avec le BE Redis, si on voulait faire un rollback il faudrait lancer un script de rollback inversé tel que :
require_relative 'lib/backends/init'
puts 'Start Sync (ROLLBACK) : '
['input','archive','error'].each do |spool|
print "* Sync : #{spool}"
fileBE = ::Backends::File::new spool: spool
redisBE = ::Backends::Redis::new spool: spool
redisBE.flush
redisBE.list.each do |entry|
fileBE.create entry: entry, data: fileBE.get({entry: entry})
end
puts ' done'
end et repasser le loader sur le BE File.
Conclusion
Faire du Flat file n'est pas une fatalité, les designs patterns sont nos amis.


